|
Tema 1. Introducción (I) |
|
¿Qué es el SQL ? |
|
Antes de empezar debes tener unas nociones básicas de
bases de datos relacionales, si quieres repasarlas haz clic aquí Como su nombre indica, el SQL nos permite realizar consultas a la base de datos. Pero el nombre se queda corto ya
que SQL además realiza funciones de definición, control y gestión de la base de datos. Las sentencias SQL se clasifican
según su finalidad dando origen a tres ‘lenguajes’ o mejor dicho
sublenguajes: |
|
|
|
|
|
|
|
Características del lenguaje |
|
Una sentencia SQL es como una frase (escrita en inglés )
con la que decimos lo
que queremos obtener y de donde obtenerlo. Todas las sentencias empiezan con un verbo (palabra reservada que indica la acción a realizar), seguido
del resto de cláusulas, algunas obligatorias y otras opcionales que completan la frase. Todas las
sentencias siguen una sintaxis para que se puedan ejecutar
correctamente, para describir esa sintaxis utilizaremos un diagrama sintáctico como el que se muestra a
continuación. |
|
Cómo interpretar un diagrama sintáctico |
|
|
Las palabras
que aparecen en mayúsculas son palabras reservadas se tienen que poner tal
cual y no se pueden utilizar para otro fin, por ejemplo, en el diagrama de la
figura tenemos las palabras reservadas SELECT, ALL,
DISTINCT, FROM, WHERE.
|

|
Una sentencia válida se construye siguiendo la línea a
través del diagrama hasta el punto que marca el final. Las líneas se siguen
de izquierda a derecha y
de arriba abajo.
Cuando se quiere alterar el orden normal se indica con una flecha. |
|
|
|
Cómo se crea una sentencia SQL en ACCESS2000 |
|
Este manual está basado en el SQL del motor de base de
datos que utiliza el Access2000, el Microsoft Jet 4.x, para que los ejemplos y ejercicios se puedan ejecutar y
probar. Para crear y después ejecutar una sentencia SQL en
Access, lo fácil es utilizar la ventana SQL de las consultas. |
|
Para crear una consulta de selección, seguir los siguientes pasos: Abrir la base de datos donde se encuentra la consulta a
crear. Hacer clic sobre el objeto Consulta que se encuentra a la izquierda de
la ventana de la base de datos. Hacer clic sobre el botón Nuevo |
|
Seleccionar Vista Diseño.
|

|
Como no queremos utilizar el generador de consultas sino
escribir nuestras propias sentencias SQL, no agregamos ninguna tabla.
|

|
Hacer clic
sobre el botón |
|

|
Si nos hemos equivocado a la hora de escribir la
sintaxis, Access nos saca un mensaje de error y muchas veces el cursor se queda posicionado en la palabra
donde ha saltado el error. Ojo, a veces el error está antes o después de
donde se ha quedado el cursor. Si no saca ningún mensaje de error, esto quiere decir
que la sentencia respeta la sintaxis definida, pero esto no quiere decir que
la sentencia esté bien, puede que no obtenga lo que nosotros queremos, en
este caso habrá que rectificar la sentencia. Guardar la consulta haciendo clic sobre el botón |

|
Tema 2. Las consultas simples (I) |
|
Objetivo |
|
Empezaremos por estudiar la sentencia SELECT, que permite recuperar datos de una o varias tablas.
La sentencia SELECT es con mucho la más compleja y potente de las sentencias
SQL. Empezaremos por ver las consultas
más simples, basadas en una sola tabla. Esta sentencia forma parte del DML (lenguaje de
manipulación de datos), en este tema veremos cómo seleccionar columnas de una tabla, cómo seleccionar filas y cómo obtener las filas ordenadas por el criterio que queramos. El resultado de la consulta es una tabla lógica, porque no se guarda en el disco sino
que está en memoria y cada vez que ejecutamos la consulta se vuelve a
calcular. Cuando ejecutamos la consulta se visualiza el resultado
en forma de tabla con columnas y filas, pues en la SELECT tenemos que indicar
qué columnas queremos que tenga el resultado y qué filas queremos seleccionar
de la tabla origen. |
|
Si no conoces todavía las tablas que utilizaremos para
los ejemplos y ejercicios clic aquí
|
|
Sintaxis de la sentencia SELECT (consultas simples) |
|
|

|
La tabla origen - FROM - |
|
Con la cláusula FROM
indicamos en qué tabla tiene que buscar la información. En este capítulo de consultas simples el resultado se
obtiene de una única tabla. La sintaxis de la cláusula es: Una especificación de tabla puede ser el nombre de una
consulta guardada (las que aparecen en la ventana de base de datos), o el
nombre de una tabla que a su vez puede tener el siguiente formato: |
|
|

|
En la cláusula IN el
nombre de la base de datos debe incluir el camino completo, la extensión (.mdb), y estar entre comillas simples. |
|
Selección de columnas |
|
La lista de columnas
que queremos que aparezcan en el resultado es lo que llamamos lista de selección y se especifica delante de la
cláusula FROM.
|

|
|
|
SELECT * FROM oficinas |
Lista todos los datos de las oficinas |
|
Cuando el nombre
de la columna o de la tabla contiene espacios en blanco, hay que poner el nombre entre corchetes [ ] y además el número de espacios
en blanco debe coincidir. Por ejemplo [codigo de cliente] no es lo mismo que
[ codigo de cliente] (el segundo lleva un espacio en blanco delante de
código) |
|
SELECT nombre, oficina, contrato |
Lista el nombre, oficina, y fecha de contrato de todos
los empleados. |
|
SELECT idfab, idproducto, descripcion,
precio |
Lista una tarifa de productos |
|
|
|
SELECT idfab AS fabricante, idproducto,
descripcion |
Como título de la primera columna aparecerá fabricante
en vez de idfab |
|
|
|
SELECT ciudad, región,
(ventas-objetivo) AS superavit |
Lista la ciudad, región y el superavit de cada oficina. |
|
SELECT idfab, idproducto, descripcion,
(existencias * precio) AS valoracion |
De cada producto obtiene su fabricante, idproducto, su
descripción y el valor del inventario |
|
SELECT nombre,
MONTH(contrato), YEAR(contrato) |
Lista el nombre, mes y año del contrato de cada
vendedor. |
|
SELECT oficina, 'tiene ventas de ',
ventas |
Listar las ventas en cada oficina con el formato: 22
tiene ventas de 186,042.00 ptas |
|
Tema 3. Las consultas multitabla (I) |
|
Introducción |
|
En este tema vamos a estudiar las consultas multitabla llamadas así porque están basadas en más de una tabla. El SQL de Microsoft Jet 4.x soporta dos grupos de
consultas multitabla: - la unión de
tablas - la composición
de tablas |
|
La unión de tablas |
|
Esta operación se utiliza cuando tenemos dos tablas con las mismas columnas y queremos obtener una nueva tabla con las filas de la primera y las filas de la
segunda. En este
caso la tabla resultante tiene las mismas columnas que la primera tabla (que
son las mismas que las de la segunda tabla). Por ejemplo tenemos una tabla de libros nuevos y una
tabla de libros antiguos y queremos una lista con todos los libros que
tenemos. En este caso las dos tablas tienen las mismas columnas, lo único que
varía son las filas, además queremos obtener una lista de libros (las
columnas de una de las tablas) con las filas que están tanto en libros nuevos
como las que están en libros antiguos, en este caso utilizaremos este tipo de
operación. Cuando hablamos de tablas pueden ser tablas reales almacenadas en la base de datos o tablas
lógicas (resultados
de una consulta), esto nos permite utilizar la operación con más frecuencia
ya que pocas veces tenemos en una base de datos tablas idénticas en cuanto a
columnas. El resultado es siempre una tabla lógica. Por ejemplo queremos en un sólo listado los productos
cuyas existencias sean iguales a cero y también los productos que aparecen en
pedidos del año 90. En este caso tenemos unos productos en la tabla de
productos y los otros en la tabla de pedidos, las tablas no tienen las mismas
columnas no se puede hacer una union de ellas pero lo que interesa realmente
es el identificador del producto (idfab,idproducto), luego por una parte
sacamos los códigos de los productos con existencias cero (con una consulta),
por otra parte los códigos de los productos que aparecen en pedidos del año
90 (con otra consulta), y luego unimos estas dos tablas lógicas. El operador que permite realizar esta operación es el
operador UNION. |
|
|
|
|

|
La composición de tablas |
|
La composición de tablas consiste en concatenar filas de una tabla con filas de
otra. En este caso obtenemos una tabla con las columnas de la primera tabla unidas
a las columnas de la segunda tabla, y las filas de la tabla resultante
son concatenaciones de filas
de la primera tabla con
filas de la segunda
tabla. |
|
|
|
|

|
A diferencia de la unión la composición permite obtener
una fila con datos de las dos tablas, esto es muy útil cuando queremos
visualizar filas cuyos datos se encuentran en dos tablas.
|
|
|
|
|

|
Existen distintos tipos de composición, aprenderemos a
utilizarlos todos y a elegir el tipo más apropiado a cada caso. Los tipos
de composición de
tablas son: . El producto cartesiano . El INNER JOIN . El LEFT
/ RIGHT JOIN |
|
Tema 4. Las consultas de resumen (I) |
|
Introducción |
|
En SQL de Microsoft Jet 4.x y de la mayoría de los
motores de bases de datos relacionales, podemos definir un tipo de consultas cuyas filas resultantes son un resumen de las filas de la tabla origen, por eso las denominamos consultas de resumen, también se conocen como consultas
sumarias. Es importante entender que las filas del resultado
de una consulta de resumen tienen una naturaleza distinta a las filas de las demás tablas resultantes de
consultas, ya que corresponden a varias filas de la tabla orgen. Para
simplificar, veamos el caso de una consulta basada en una sola tabla, una
fila de una consulta 'no resumen' corresponde a una fila de la tabla origen,
contiene datos que se encuentran en una sola fila del origen, mientras que una fila de una
consulta de resumen corresponde a un resumen de varias filas de la tabla origen, esta diferencia es lo que va a
originar una serie de restricciones que sufren las consultas de resumen y que
veremos a lo largo del tema. En el ejemplo que viene a continuación tienes un ejemplo
de consulta normal en la que se visualizan las filas de la tabla oficinas
ordenadas por region, en este caso cada fila del resultado se corresponde con
una sola fila de la tabla oficinas, mientras que la segunda consulta es una
consulta resumen, cada fila del resultado se corresponde con una o varias
filas de la tabla oficinas. |
|
|

|
Las
consultas de resumen introducen dos nuevas cláusulas a la sentencia SELECT, la cláusula GROUP BY y la cláusula
HAVING, son
cláusulas que sólo se pueden utilizar en una consulta de
resumen, se tienen que escribir entre la
cláusula WHERE y la
cláusula ORDER BY y tienen la siguiente sintaxis: |
|
|

|
Las detallaremos en la página siguiente del tema,
primero vamos a introducir otro concepto relacionado con las consultas de
resumen, las funciones de columna. |
|
Funciones de columna |
|
En la lista de selección de una consulta de resumen
aparecen funciones de
columna también
denominadas funciones de dominio agregadas. Una
función de columna se
aplica a una columna
y obtiene un valor que resume
el contenido de la columna. Tenemos las siguientes funciones de columna: |
|
|

|
El argumento de la función indica con qué
valores se tiene que
operar, por eso expresión suele ser un nombre de columna, columna
que contiene los valores a resumir, pero también puede ser cualquier
expresión válida que devuelva una lista de valores.
|
|
SELECT
SUM(ventas) |
Obtiene
una sola fila con el resultado de sumar todos los valores de la columna
ventas de la tabla oficinas. |
|
|
|
Si tenemos
esta tabla: |
La
consulta |
devuelve: |
En este
caso los ceros entran en la media por lo que sale igual a 4 |
|
Con esta
otra tabla: |
SELECT AVG(col1) AS media |
devuelve: |
En este
caso los ceros se han sustituido por valores nulos y no entran en el cálculo
por lo que la media sale igual a 6 |


|
Ejemplo: |
|
|
|
SELECT
(AVG(ventas) * 3) + SUM(cuota) |
SELECT AVG(SUM(ventas)) |
|
Selección en el origen de datos. |
|
Si queremos eliminar del origen de datos algunas filas, basta incluir
la cláusula WHERE que ya conocemos después de la
cláusula FROM. SELECT
SUM(ventas) |
|
Origen múltiple. |
|
Si los datos
que necesitamos utilizar para obtener nuestro resumen se encuentran en varias tablas, formamos el origen de datos adecuado en la cláusula FROM como si fuera una consulta multitabla normal. SELECT
SUM(empleados.ventas), MAX(objetivo) |
|
Tema 5. Las subconsultas (I) |
|
Definiciones |
|
Una subconsulta
es una sentencia SELECT que aparece dentro de otra sentencia SELECT que llamaremos consulta principal. Se puede encontrar en la lista de selección, en
la cláusula WHERE o en la cláusula HAVING de la consulta principal. Una subconsulta tiene la misma sintaxis que una
sentencia SELECT normal exceptuando que aparece encerrada entre paréntesis, no puede contener la cláusula ORDER BY, ni puede ser la UNION de varias sentencias SELECT, además tiene algunas restricciones en cuanto a número de
columnas según el lugar donde aparece en la consulta principal. Estas
restricciones las iremos describiendo en cada caso. Cuando se ejecuta una consulta que contiene una
subconsulta, la
subconsulta se ejecuta por cada fila de la consulta principal. Se aconseja no utilizar campos calculados en las
subconsultas, ralentizan la consulta. Las consultas que utilizan subconsultas suelen ser más fáciles de interpretar por el
usuario. |
|
Referencias externas |
|
A menudo, es necesario, dentro del cuerpo de una
subconsulta, hacer referencia al valor de una columna en la fila actual de la
consulta principal, ese nombre de columna se denomina referencia externa.
|
|
En este ejemplo la consulta principal es SELECT... FROM empleados. ¿Qué pasa cuando se ejecuta la consulta principal? Si quitamos la cláusula WHERE de la subconsulta obtenemos la fecha del primer pedido de
todos los pedidos no del empleado correspondiente. |
|
Anidar subconsultas |
|
Las
subconsultas pueden anidarse de forma que una subconsulta aparezca en la cláusula
WHERE (por ejemplo) de otra subconsulta que a su vez forma parte de otra
consulta principal. En la práctica, una consulta consume mucho más tiempo y
memoria cuando se incrementa el número de niveles de anidamiento. La consulta
resulta también más difícil de leer , comprender y mantener cuando contiene
más de uno o dos niveles de subconsultas. |
|
SELECT numemp, nombre |
|
En este
ejemplo, por cada linea de pedido se calcula la subconsulta de clientes, y
esto se repite por cada empleado, en el caso de tener 10 filas de empleados y
200 filas de pedidos (tablas realmente pequeñas), la subconsulta más interna
se ejecutaría 2000 veces (10 x 200). |
|
Subconsulta en la lista de selección |
|
Cuando la subconsulta aparece en la lista de selección de la consulta principal, en este
caso la subconsulta, no
puede devolver varias filas ni varias columnas, de lo contrario se da un mensaje de
error. Muchos SQLs no permiten que una subconsulta aparezca en
la lista de selección de la consulta principal pero eso no es ningún problema
ya que normalmente se puede obtener lo mismo utilizando como origen de datos
las dos tablas. El ejemplo anterior se puede obtener de la siguiente forma: |
|
SELECT
numemp, nombre, MIN(fechapedido) |
|
En la cláusula FROM |
|
En la cláusula FROM se puede encontrar una sentencia
SELECT encerrada entre paréntesis pero más que subconsulta sería una consulta ya que no se ejecuta para cada fila
de la tabla origen sino que se ejecuta una sola vez al principio, su
resultado se combina con las filas de la otra tabla para formar las filas
origen de la SELECT primera y no admite referencias externas. En la cláusula FROM vimos que se podía poner un nombre
de tabla o un nombre de consulta, pues en vez de poner un nombre de consulta
se puede poner directamente la sentencia SELECT correspondiente a esa
consulta encerrada entre paréntesis. |
|
Subconsulta en las cláusulas WHERE y HAVING |
|
Se suele
utilizar subconsultas en las cláusulas WHERE o HAVING cuando los datos que
queremos visualizar están en una tabla pero para seleccionar las filas de esa
tabla necesitamos un dato que está en otra tabla. |
|
Ejemplo: En este ejemplo listamos el número y nombre de los
empleados cuya fecha de contrato sea igual a la primera fecha de todos los
pedidos de la empresa. |
|
En una cláusula
WHERE / HAVING tenemos siempre una condición y la subconsulta actúa de
operando dentro de esa condición. |
|
Tema 6. Actualización de datos (I) |
|
Introducción |
|
Hasta ahora hemos estudiado el cómo recuperar datos
almacenados en las tablas de nuestra base de datos. En este tema vamos a tratar
el de la actualización de esos datos, es decir insertar nuevas filas, borrar filas o
cambiar el contenido de las filas de una tabla. Estas operaciones modifican los datos almacenados en las
tablas pero no su estructura, ni su definición. Empezaremos por ver cómo insertar nuevas filas (con la sentencia INSERT INTO), veremos una variante (la sentencia
SELECT... INTO), después veremos cómo borrar filas de una tabla (con la sentencia DELETE) y por último cómo modificar el contenido de las filas de una
tabla (con la sentencia UPDATE). Si trabajamos en un entorno multiusuario, todas estas operaciones se podrán
realizar siempre que
tengamos los permisos correspondientes. |
|
Insertar una fila INSERT INTO...VALUES |
|
La inserción de nuevos datos en una tabla se realiza añadiendo filas enteras a la tabla, la sentencia SQL que lo permite es
la orden INSERT INTO. La inserción se puede realizar de una fila o de varias
filas de golpe, veremos las dos opciones por separado y empezaremos por la inserción de una fila. La sintaxis es la siguiente: |
|
|

|
Esta sintaxis se utiliza para insertar una sola fila
cuyos valores indicamos después de la palabra reservada VALUES. En castellano la sentencia se
leería: INSERTA EN
destino...VALORES ....
Ejemplo: Observar en el ejemplo que los valores de tipo texto se
encierran entre comillas simples ' ' (también se pueden emplear las comillas
dobles " ") y que la fecha de contrato se encierra entre
almohadillas # # con el formato mes/dia/año. Como no tenemos valor para los
campos oficina y director (a este nuevo empleado todavía no se le ha asignado
director ni oficina) utilizamos la palabra reservada NULL. Los valores numéricos se escriben tal cual, para
separar la parte entera de la parte decimal hay que utilizar siempre el punto
independientemente de la configuración que tengamos.
El ejemplo anterior se podría escribir de la siguiente
forma: Observar que ahora hemos variado el orden de los valores
y los nombres de columna no siguen el mismo orden que en la tabla origen, no
importa, lo importante es poner los valores en el mismo orden que las
columnas que enunciamos. Como no enunciamos las columnas oficina y director
se rellenarán con el valor nulo (porque es el valor que tienen esas columnas
como valor predeterminado).
|
|
|
|
Tema 7. Tablas de referencias cruzadas (I) |
|
Introducción |
|
Por ejemplo queremos obtener las ventas mensuales de
nuestros empleados. Tenemos que diseñar una consulta sumaria calculando la
suma de los importes de los pedidos agrupando por empleado y mes de la venta.
La consulta sería: SELECT rep as empleado, month(fechapedido) as mes,
sum(importe) as vendido El resultado sería la tabla que aparece a la derecha: |
|
|
La consulta
quedaría mucho más elegante y clara presentando los datos en un formato más
compacto como el siguiente: |
|

|
|
|
Pues este último resultado se obtiene mediante una
consulta de referencias cruzadas. Observar que una de las columnas de
agrupación (rep) sigue definiendo las filas que aparecen (hay una fila por
cada empleado), mientras que la otra columna de agrupación (mes) ahora sirve
para definir las otras columnas, cada valor de mes define una columna en el
resultado, y la celda en la intersección de un valor de rep y un valor de mes
es la columna resumen, la que contiene la función de columna (la suma de
importe). Las consultas de referencias cruzadas se pueden crear
utilizando el asistente, es mucho más cómodo pero es útil saber cómo hacerlo
directamente en SQL por si queremos variar algún dato una vez realizada la
consulta con el asistente o si queremos definir una consulta de referencias
cruzadas que no se puede definir con el asistente. |

|
La sentencia TRANSFORM |
|
La sentencia TRANSFORM
es la que se utiliza para
definir una consulta de referencias cruzadas. La sintaxis es la siguiente: |
|
|

|
|
|
La sentencia quedaría de la siguiente forma: TRANSFORM Sum(importe) Lo mejor para montar una consulta de referencias
cruzadas en SQL es pensar la sumaria normal y luego distribuir los términos
según corresponda. |
|
Tema 8. El DDL, lenguaje de definición de datos (I) |
|
Introducción |
|
Hasta ahora hemos estudiado las sentencias que forman
parte del DML (Data Management Language) lenguaje de manipulación de datos,
todas esas sentencias sirven para recuperar, insertar, borrar, modificar los
datos almacenados en la base de datos; lo que veremos en este tema son las
sentencias que afectan a la estructura de los datos. El DDL (Data
Definition Language) lenguaje de definición de datos es la parte del SQL que más varía de un sistema a otro ya que esa area tiene que ver con
cómo se organizan internamente los datos y eso, cada sistema lo hace de una
manera u otra. Así como el DML de Microsoft Jet incluye todas las
sentencias DML que nos podemos encontrar en otros SQLs (o casi todas), el DDL
de Microsoft Jet en cambio contiene menos instrucciones que otros sistemas. |
|
CREATE TABLE |
|
La sentencia CREATE TABLE sirve para crear la estructura de una tabla no para rellenarla con datos, nos
permite definir las
columnas que tiene y ciertas restricciones que deben cumplir esas columnas. La sintaxis es la siguiente: |
|
|
|
|

|
nbtabla: nombre de la tabla que
estamos definiendo nbcol: nombre de la columna que
estamos definiendo tipo: tipo de dato
de la columna, todos los datos almacenados en la columna deberán ser de ese
tipo. Para ver qué tipos de datos se pueden emplear haz clic aquí Una restricción consiste en la definición de una característica adicional que tiene una
columna o una
combinación de columnas, suelen ser características como valores no nulos
(campo requerido), definición de índice sin duplicados, definición de clave
principal y definición de clave foránea (clave ajena o externa, campo que
sirve para relacionar dos tablas entre sí). restricción1: una restricción de tipo 1 es una restricción que aparece dentro de la definición de la columna después del tipo de dato y afecta a una
columna, la que se
está definiendo. restricción2: una restricción de tipo 2 es una restricción que se define después de definir todas las columnas de la tabla y afecta a una columna o a una combinación de columnas. Para escribir una sentencia CREATE TABLE se empieza por indicar el nombre de la tabla que queremos crear y a continuación entre paréntesis indicamos separadas por comas las definiciones de
cada columna de la
tabla, la definición de una columna consta de
su nombre, el tipo de
dato que tiene y podemos añadir si queremos una serie de especificaciones que deberán cumplir los datos
almacenados en la columna, después
de definir cada una de las columnas que compone la tabla se pueden añadir una serie de restricciones, esas restricciones son las mismas
que se pueden indicar para cada columna pero ahora pueden afectar a más de una columna por eso tienen una sintaxis
ligeramente diferente. |
|
|

|
La cláusula NOT NULL
indica que la columna no
podrá contener un valor nulo, es decir que se deberá rellenar obligatoriamente y con un
valor válido (equivale a la propiedad requerido Sí de las propiedades del
campo). La cláusula CONSTRAINT
sirve para definir una restricción que se podrá eliminar cuando
queramos sin tener que borrar la columna. A cada restricción se le asigna un
nombre que se utiliza para identificarla y para poder eliminarla cuando se
quiera. Como restricciones tenemos la de clave primaria (clave
principal), la de índice único (sin duplicados), la de valor no nulo, y la de
clave foránea. La cláusula PRIMARY KEY se
utiliza para definir la columna como clave principal de la tabla. Esto supone que la columna no puede contener valores nulos ni pueden haber
valores duplicados
en esa columna, es decir que dos filas no pueden tener el mismo valor en esa
columna. En una tabla no pueden haber varias claves principales, por lo que no podemos incluir la
cláusula PRIMARY KEY más de una vez, en caso contrario la
sentencia da un error. No hay que confundir la definición de varias claves
principales con la definición de una clave principal compuesta por varias
columnas, esto último sí está permitido y se define con una restricción de
tipo 2. La cláusula UNIQUE
sirve para definir un índice
único sobre la
columna. Un índice único es un índice que no permite valores duplicados, es decir que si una columna tiene
definida un restricción de UNIQUE
no podrán haber dos filas con el mismo valor en esa columna. Se suele emplear
para que el sistema compruebe el mismo que no se añaden valores que ya
existen, por ejemplo si en una tabla de clientes queremos asegurarnos que dos
clientes no puedan tener el mismo D.N.I. y la tabla tiene como clave
principal un código de cliente, definiremos la columna dni con la restricción
de UNIQUE. La cláusula NOT NULL
indica que la columna no puede contener valores nulos, cuando queremos
indicar que una columna no puede contener el valor nulo lo podemos hacer sin
poner la cláusula CONSTRAINT, o utilizando una cláusula CONSTRAINT. La última restricción que podemos definir sobre una
columna es la de clave foránea, una clave foránea es una columna o conjunto de columnas que contiene un valor que hace
referencia a una fila de otra tabla, en una restricción de tipo 1 se puede definir con la
cláusula REFERENCES, después de la palabra reservada
indicamos a qué tabla hace referencia, opcionalmente podemos indicar entre
paréntesis el nombre de la columna donde tiene que buscar el valor de
referencia, por defecto coge la clave principal de la tabla2, si el valor que
tiene que buscar se encuentra en otra columna de tabla2, entonces debemos
inidicar el nombre de esta columna entre paréntesis, además sólo podemos
utilizar una columna que esté definida con una restricción de UNIQUE, si la columna2 que indicamos no
está definida sin duplicados, la sentencia CREATE nos dará un error. Si quieres repasar conceptos de clave
foránea e integridad referencial haz clic aquí Para seguir con la instrucción CREATE TABLE pasa a la siguiente página... |
|
Ejemplo: CREATE TABLE tab1 ( Con este ejemplo estamos creando la tabla tab1
compuesta por: una columna llamada col1 de tipo entero definida como
clave principal, una columna col2 que puede almacenar hasta 25
caracteres alfanuméricos y no puede contener valores nulos, una columna col3
de hasta 10 caracteres que no podrá contener valores repetidos, una columna col4
de tipo entero sin ninguna restricción, y una columna col5 de tipo
entero clave foránea que hace referencia a valores de la clave principal de
la tabla tab2. |
|
Conceptos básicos de integridad referencial. |
|
Introducción |
|
|
La integridad
referencial es un
sistema de reglas que utilizan la mayoría de las bases
de datos relacionales para asegurarse que los registros de tablas relacionadas son válidos y que no se borren o cambien datos
relacionados de forma accidental produciendo errores de integridad. Primero repasemos un poco los tipos de relaciones. |
|
Tipos de relaciones. |
|
|
Entre dos tablas de cualquier base de datos relacional
pueden haber dos tipos de relaciones, relaciones uno a uno y relaciones uno a
muchos:
Por ejemplo: tenemos dos tablas una de profesores y otra
de departamentos y queremos saber qué profesor es jefe de qué departamento,
tenemos una relación uno a uno entre las dos tablas ya que un departamento
tiene un solo jefe y un profesor puede ser jefe de un solo departamento.
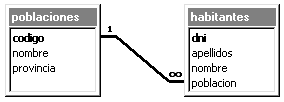
Por ejemplo: tenemos dos tablas una con los datos de
diferentes poblaciones y otra con los habitantes, una población puede tener más
de un habitante, pero un habitante pertenecerá (estará empadronado) en una
única población. En este caso la tabla principal será la de poblaciones y la
tabla secundaria será la de habitantes. Una población puede tener varios
habitantes pero un habitante pertenece a una sola población. Esta relación se
representa incluyendo en la tabla 'hijo' una columna que se corresponde con
la clave principal de la tabla 'padre', esta columna es lo denominamos clave
foránea (o clave ajena o clave externa). Una clave foránea es pues un campo de una tabla que
contiene una referencia a un registro de otra tabla. Siguiendo nuestro
ejemplo en la tabla habitantes tenemos una columna población que contiene el
código de la población en la que está empadronado el habitante, esta columna
es clave ajena de la tabla habitantes, y en la tabla poblaciones tenemos una
columna codigo de poblacion clave principal de la tabla. |
|
|
|
Por ejemplo: tenemos dos tablas una con los datos de clientes
y otra con los artículos que se venden en la empresa, un cliente podrá
realizar un pedido con varios artículos, y un artículo podrá ser vendido a
más de un cliente. No se puede definir entre clientes y artículos,
hace falta otra tabla (por ejemplo una tabla de pedidos) relacionada con
clientes y con artículos. La tabla pedidos estará relacionada con cliente por
una relación uno a muchos y también estará relacionada con artículos por un
relación uno a muchos. |
|
|

|
Integridad referencial |
|
|
Cuando se define una columna como clave foránea, las
filas de la tabla pueden contener en esa columna o bien el valor nulo (ningún
valor), o bien un valor que existe en la otra tabla, un error sería asignar a
un habitante una población que no está en la tabla de poblaciones. Eso es lo
que se denomina integridad
referencial y
consiste en que los
datos que referencian otros (claves foráneas) deben ser correctos. La integridad referencial hace que el sistema gestor de la base
de datos se asegure de que no hayan en las claves foráneas valores que no
estén en la tabla principal. La integridad referencial se activa en
cuanto creamos una clave foránea y a partir de ese momento se comprueba cada vez que se
modifiquen datos que puedan alterarla. ¿ Cuándo se pueden producir errores en
los datos?
Asociada a la integridad referencial están los conceptos
de actualizar los registros en cascada y eliminar registros en cascada. |
|
Actualización y borrado en cascada |
|
|
El actualizar y/o eliminar registros en cascada, son
opciones que se definen cuando definimos la clave foránea y que le indican al
sistema gestor qué hacer en los casos comentados en el punto anterior.
Si no se tiene definida esta opción, no se puede cambiar
los valores de la clave principal de la tabla principal. En este caso, si
intentamos cambiar el valor 1 del codigo de la tabla de poblaciones , no se
produce el cambio y el sistema nos devuelve un error o un mensaje que los
registros no se han podido modificar por infracciones de clave.
Si no se tiene definida esta opción, no se pueden borrar
registros de la tabla principal si estos tienen registros relacionados en la
tabla secundaria. En este caso, si intentamos borrar la población Onteniente,
no se produce el borrado y el sistema nos devuelve un error o un mensaje que
los registros no se han podido eliminar por infracciones de clave. |
|
Conceptos básicos sobre índices. |
|
Definición |
|
|
Un índice en informática es como el índice de un libro
donde tenemos los capítulos del libro y la página donde empieza cada
capítulo. No vamos a entrar ahora en cómo se implementan los índices
internamente ya que no entra en los objetivos del curso pero sí daremos unas
breves nociones de cómo se definen, para qué sirven y cuándo hay que
utilizarlos y cuando no. Un índice es una estructura de datos que permite recuperar las filas de una tabla
de forma más rápida
además de proporcionar
una ordenación
distinta a la natural de la tabla. Un índice se define sobre una columna o sobre un grupo de
columnas, y las
filas se ordenarán según los valores contenidos en esas columnas. Por
ejemplo, si definimos un índice sobre la columna poblacion de la tabla
de clientes, el índice permitirá recuperar los clientes ordenados por
orden alfabético de población. Si el índice se define sobre varias columnas, los registros se ordenarán por la primera columna, dentro de un
mismo valor de la primera columna se ordenarán por la segunda columna, y así sucesivamente. Por ejemplo si
definimos un índice sobre las columnas provincia y poblacion se
ordenarán los clientes por provincia y dentro de la misma provincia por
población, aparecerían los de ALICANTE Denia, ALICANTE Xixona, VALENCIA
Benetússer, VALENCIA Oliva. El orden de las columnas dentro de un índice es importante, si retomamos el ejemplo anterior y
definimos el índice sobre poblacion y provincia, aparecerían
los de VALENCIA Benetusser, ALICANTE Denia, VALENCIA Oliva, ALICANTE Xixona.
Ahora se ordenan por población y los clientes de la misma población se
ordenarían por el campo provincia. |
|
Ventajas e inconvenientes |
|
|
Si una tabla tiene definido un índice sobre una columna se puede localizar mucho más rápidamente
una fila que tenga
un determinado valor en esa columna. Recuperar las filas de una tabla de forma ordenada por la columna en cuestión también
será mucho más rápido. |
|
Al ser el índice una estructura de datos adicional a la
tabla, ocupa un poco más de espacio en disco. Cuando se añaden, modifican o se borran filas de la
tabla, el sistema debe actualizar los índices afectados por esos cambios lo
que supone un tiempo de
proceso mayor. Por estas razones no es
aconsejable definir
índices de forma indiscriminada. Los inconvenientes comentados en este punto no son nada
comparados con las ventajas si la columna sobre la cual se define el índice
es una columna que se va a utilizar a menudo para buscar u ordenar las filas
de la tabla. Por eso una regla bastante acertada es definir índices sobre columnas que se vayan a utilizar a menudo para recuperar u ordenar las filas de una tabla. El Access de hecho crea automáticamente índices sobre
las columnas claves principales y sobre las claves foráneas ya que se supone
que se utilizan a menudo para recuperar filas concretas. |
|
Tipos de datos. |
|
Estos son los tipos de datos que soporta el SQL de Microsoft®
Jet versión 4.0 Los sinónimos son palabras equivalentes al tipo de dato
indicado. El tamaño indica cuánto ocupará una columna del tipo
indicado. |
|
Tipo de dato |
Sinónimos |
Tamaño |
Descripción |
|
BINARY |
VARBINARY |
1 byte por carácter |
Se puede almacenar cualquier tipo de datos
en un campo de este tipo. Los datos no se traducen (por ejemplo, a texto). La
forma en que se introducen los datos en un campo binario indica cómo
aparecerán al mostrarlos. |
|
BIT |
BOOLEAN |
1 byte |
Valores Sí y No, y campos que contienen
solamente uno de dos valores. |
|
TINYINT |
INTEGER1 |
1 byte |
Un número entero entre 0 y 255. |
|
COUNTER |
AUTOINCREMENT |
|
Se utiliza para campos contadores cuyo valor
se incrementa automáticamente al crear un nuevo registro. |
|
MONEY |
CURRENCY |
8 bytes |
Un número entero comprendido entre |
|
DATETIME |
DATE |
8 bytes |
Una valor de fecha u hora entre los años 100
y 9999 |
|
UNIQUEIDENTIFIER |
GUID |
128 bits |
Un número de identificación único utilizado
con llamadas a procedimientos remotos. |
|
DECIMAL |
NUMERIC |
17 bytes |
Un tipo de datos numérico exacto con valores
comprendidos entre 1028 - 1 y - 1028 - 1. Puede definir la precisión (1 - 28)
y la escala (0 - precisión definida). La precisión y la escala
predeterminadas son 18 y 0, respectivamente. |
|
REAL |
SINGLE |
4 bytes |
Un valor de coma flotante de precisión
simple con un intervalo comprendido entre – 3,402823E38 y – 1,401298E-45 para
valores negativos, y desde 1,401298E-45 a 3,402823E38 para valores positivos,
y 0. |
|
FLOAT |
DOUBLE |
8 bytes |
Un valor de coma flotante de precisión doble
con un intervalo comprendido entre – 1,79769313486232E308 y –
4,94065645841247E-324 para valores negativos, y desde 4,94065645841247E-324 a
1,79769313486232E308 para valores positivos, y 0. |
|
SMALLINT |
SHORT |
2 bytes |
Un entero corto entre – 32.768 y 32.767. |
|
INTEGER |
LONG |
4 bytes |
Un entero largo entre – 2.147.483.648 y
2.147.483.647. |
|
IMAGE |
LONGBINARY |
Lo que se requiera |
Desde cero hasta un máximo de 2.14
gigabytes. |
|
TEXT |
LONGTEXT |
2 bytes por carácter. (Consulte las notas). |
Desde cero hasta un máximo de 2.14
gigabytes. |
|
CHAR |
TEXT(n) |
2 bytes por carácter. (Consulte las notas). |
Desde cero a 255 caracteres. |
|
Notas:
Los caracteres de los campos definidos como TEXT
(también conocidos como MEMO) o CHAR (también conocidos como TEXT(n) con una
longitud específica) se almacenan en el formato de representación Unicode.
Los caracteres Unicode requieren siempre dos bytes para el almacenamiento de
cada carácter. Para las bases de datos de Microsoft Jet ya existentes que
contengan principalmente datos de tipo carácter, esto puede significar que el
tamaño del archivo de base de datos sea casi el doble cuando se convierta al
formato Microsoft Jet 4.0. Sin embargo, la representación Unicode de muchos
juegos de caracteres, antes denominados juegos de caracteres de un solo byte
(SBCS), puede comprimirse fácilmente a caracteres de un solo byte. Si define
una columna CHAR con el atributo COMPRESSION, los datos se comprimirán
automáticamente a medida que se almacenen y se descomprimirán cuando se
recuperen de la columna. |
|
Los caracteres Unicode y su compresión. |
|
En ACCESS 2000 se utiliza el formato de representación
de caracteres Unicode, los caracteres Unicode requieren siempre dos bytes
para cada carácter lo que permite una gama más amplia de caracteres. Para las bases de datos de Microsoft® Jet ya existentes
que contengan principalmente datos de tipo carácter, esto puede significar
que el tamaño del archivo de base de datos sea casi el doble cuando se
convierta al formato Microsoft Jet versión 4.0. Sin embargo, la
representación Unicode de muchos juegos de caracteres, antes denominados
juegos de caracteres de un solo byte (SBCS), puede comprimirse fácilmente a
caracteres de un solo byte. Si se define una columna CHARACTER con el
atributo WITH COMPRESSION (propiedad Compresión Unicode), los datos se
comprimirán automáticamente cuando se almacenen y se descomprimirán cuando se
recuperen de la columna. Las columnas MEMO también pueden ser definidas de modo
que almacenen datos en formato comprimido. No obstante, existe una
restricción. Sólo se comprimirán las instancias de columnas MEMO que, tras la
compresión, ocupen 4.096 bytes o menos. El resto de instancias de columnas
MEMO quedarán sin comprimir. Esto significa que, dentro de una tabla
determinada, para una columna MEMO dada, algunos datos pueden estar
comprimidos y otros no. |
|
Fuente: Datos extraidos de la ayuda de Microsoft Access2000. |
|
|